
Reinforcement Learning – An Introduction
1. Introduction
Reinforcement Learning (RL) is a branch of Machine Learning where an agent learns to make decisions by interacting with an environment.
Unlike supervised learning (where models learn from labeled examples) or unsupervised learning (where models find hidden structures in data), reinforcement learning is about trial and error with feedback.
At its core, RL is inspired by how humans and animals learn. Imagine teaching a dog to sit:
- If it follows the command, you give it a treat (positive reward).
- If it doesn’t, no treat (no reward or negative feedback).
Over time, the dog learns which actions lead to rewards. Similarly, in RL, the agent gradually improves its behavior to maximize long-term rewards.
RL has become very popular because of its success in:
- Games: Beating world champions in Chess, Go, and video games.
- Robotics: Teaching robots to walk, grasp, or navigate.
- Real-world systems: Optimizing traffic signals, recommending content, or managing resources.
2. Key Concepts & Terminologies
Understanding RL requires learning some important terms. Let’s break them down:
-
Agent: The learner or decision-maker.
Example: A robot navigating a maze. -
Environment: The world the agent interacts with.
Example: The maze itself with walls and pathways. -
State (S): A snapshot of the environment at a given time.
Example: The robot’s current position in the maze. -
Action (A): Choices the agent can take.
Example: Move forward, turn left, turn right. -
Reward (R): Feedback from the environment.
Example: +10 for reaching the goal, -1 for hitting a wall. -
Policy (π): The strategy that defines which action to take in each state.
Example: “If I see a wall, turn right.” -
Value Function: Predicts how good a state (or action) is in terms of long-term rewards.
-
Q-Value (Action-Value Function): Value of taking a specific action in a specific state.
Example: “If I am two steps from the goal, moving forward is worth more than turning.”
3. Learning Process
Reinforcement Learning is built on a simple cycle:
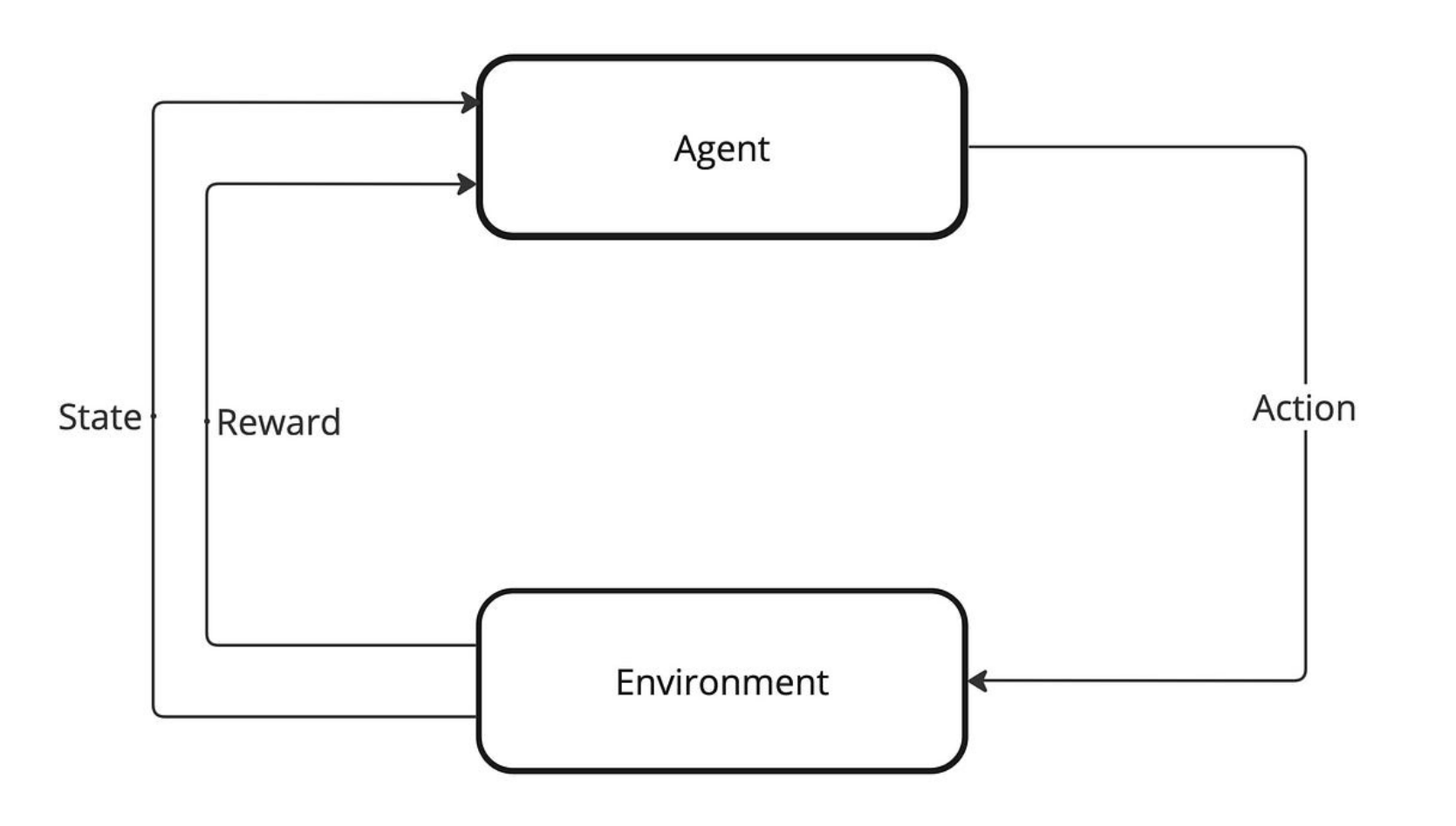
- The agent observes the current state of the environment.
- It takes an action.
- The environment responds with a new state and a reward.
- The agent updates its knowledge (policy or value estimates).
This repeats until the task ends (called an episode). Over many episodes, the agent improves.
Exploration vs. Exploitation
A key challenge in RL is deciding when to:
- Explore: Try new actions to discover better strategies.
- Exploit: Use known strategies that already give high rewards.
Finding the right balance between exploration and exploitation is crucial for effective learning.
4. Applications of RL
Reinforcement Learning is not just theory—it powers many exciting technologies:
-
Games:
- AlphaGo defeated the world champion in Go.
- AI systems master complex video games like StarCraft and Dota.
-
Robotics:
- Robots learn to walk, fly drones, follow lines, or grasp objects.
-
Self-Driving Cars:
- Learning to navigate roads, avoid obstacles, and follow traffic rules.
-
Industry & Daily Life:
- Smart assistants recommending music or movies.
- Optimizing warehouse robots and logistics.
- Energy management in smart grids.
5. Popular Algorithms in RL
Here are some of the most well-known RL algorithms, explained briefly:
-
Q-Learning
- A simple value-based method where the agent learns a table of values for state-action pairs.
- Goal: Find the best action for each state to maximize rewards.
-
SARSA (State–Action–Reward–State–Action)
- Similar to Q-Learning, but updates values based on the actual action chosen, making it more conservative.
-
Deep Q-Networks (DQN)
- Uses deep neural networks to approximate Q-values, allowing RL to work on large and complex environments like video games.
-
Policy Gradient Methods
- Instead of learning values, these methods directly learn the policy (the strategy itself).
- Useful for continuous action spaces like controlling a robotic arm.
These algorithms form the foundation of modern RL research and applications.
6. References
Here are some useful references for beginners: